.svg)
29 juli 2022
Each day, at Randstad, we employ industry-scale recommender systems to recommend thousands of job seekers to our clients, and the other way around; vacancies to job seekers. Our job recommender system is based on a heterogeneous collection of input data: curriculum vitaes (resumes) of job seekers, vacancy texts (job descriptions), and structured data (e.g., the location of a job seeker or vacancy).
The goal of our system is to recommend the best job seekers to each open vacancy.
In a recently published paper we explore and describe methods for constructing useful embeddings of textual information in vacancies and resumes.
challenges
Several challenges arise when matching jobs to job seekers through textual resume and vacancy data.
Noisy Data
First, the data we work with is inherently noisy. On the one hand, resumes are user-generated data, usually (but not always) in PDF format. It goes without saying that parsing those files to plain text can be a challenge in itself, and was therefore considered out of scope. On the other hand, in our case vacancies are composed of structured formatted text.
Complementary Data
Second, the nature of the data differs. Most NLP research in text similarity is based on the assumption that two pieces of information are the same but written differently. However, in our case the two documents do not express the same information, but complement each other like pieces of a puzzle. Our goal is to match two complementary pieces of textual information, that may not exhibit direct overlap/similarity.
Multilinguality
Third, as a multinational corporation that operates all across the globe, developing separate models for each market and language does not scale. Therefore, a desired property of our system is multilinguality; a system that will support as many languages as possible.
In addition, as it is common to have English resumes in non-English countries (e.g., in the Dutch market around 10% of resumes are in English), cross-linguality is another desired property, e.g., being able to match English resumes to Dutch vacancies.
dataset creation
We have a rich history of interaction between consultants (recruiters) and job seekers (candidates). We define a positive signal as any point of contact between a job seeker and consultant (e.g., a phone call, interview, job offer, etc.). Negative signals are defined by job seekers who submit their profile, but get rejected by a consultant without any interaction (i.e., consultant looks at the job seeker's profile, and rejects).
In addition, since we have an unbalanced dataset, for each vacancy we add random negative samples, which we draw randomly from our job seeker pool. This is done in spirit with other works, which also complement historical data with random negative pairs.
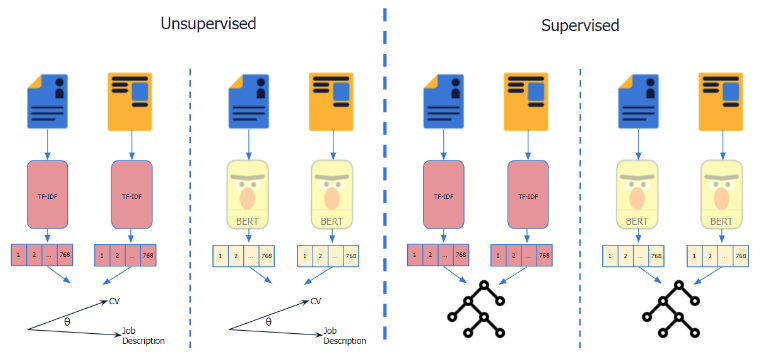
baseline
Unsupervised
Our first baselines rely on unsupervised feature representations. More specifically, we represent both our vacancies and resumes as either
- TF-IDF weighted vectors
- pre-trained BERT embeddings
We then compute cosine similarities between pairs of resumes and vacancies, and consider the cosine similarity as the predicted ``matching score''.
Our TF-IDF vectors have 768 dimensions, which is equal to the dimensionality of BERT embeddings. We fitted our TF-IDF weights on the training set, comprising both vacancy and resume data. As for BERT models we use the pre-trained on Wikipedia from the HuggingFace library. These unsupervised baselines help us to assess the extent to which the vocabulary gap is problematic, i.e., if vacancies and resumes use completely different words, both bag of words-based approaches such as TF-IDF weighting and embedding representations of these different words will likely show low similarity. Formulated differently, if word overlap or proximity between vacancies and resumes is meaningful, these baselines would be able to perform decently.
Supervised
Next, we present our two supervised baselines, where we employ a random forest classifier that is trained on top of the feature representation described in the unsupervised section. These supervised baselines are trained on our 80% train split, using the default parameters given by the scikit-learn library.
We add these supervised methods and compare them to the previously described unsupervised baselines to further establish the extent of the aforementioned vocabulary gap, and the extent in which the heterogeneous nature of the two types of documents plays a role.
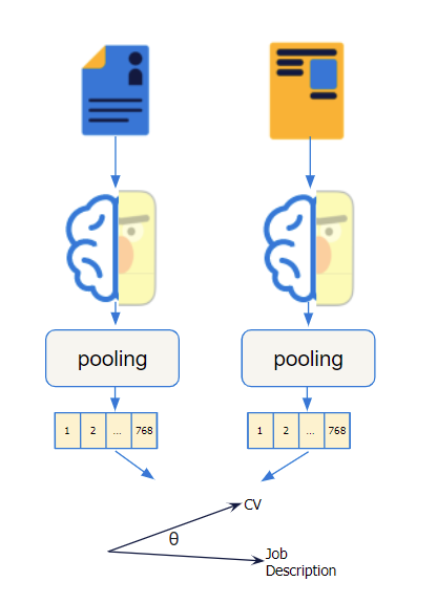
conSultantBERT
Finally, we present our fine-tuned embedding model; conSultantBERT, which we fine-tune using the regression objective, as illustrated in figure below.
results
In the figure below we see a few examples for sentences that a candidate might write “I worked …” and few examples for vacancy “We are looking for …”. In order to demonstrate cross lingual and multilingual the same examples are written in both English and Dutch.

TF-IDF
With TFIDF we can see that there is no match at all. This is due to the vocabulary gap, so by definition TFIDF can not match between “warehouse” and “logistic worker”.

BERT
To solve the vocabulary gap we introduced BERT.

Which we see does find similarity between candidate and vacancy sentences. However, it also hardly separates between the positive and negative pairs.
Moreover, we can see a slight clustering around languages, so Dutch sentences have comparatively higher similarity to Dutch sentences, and likewise English sentences are more similar to each other.
conSultantBERTRegressor
On the Figure above we observe that the vocabulary gap is bridged, cross-lingual sentences are paired properly (e.g “I worked in a warehouse for 10 years” and “We zijn op zoek naar een getalenteerde logistiek medewerker” have high score), and finally, both Dutch to Dutch and English to English sentences are properly scored, too, thus achieving our desired property of multilinguality.
final notes
In this work we experimented with various ways to construct embeddings of resume and vacancy texts. We propose to fine-tune the BERT model using the Siamese SBERT framework on our large real-world dataset with high quality labels for resume-vacancy matches derived from our consultants' decisions. We show our model beat our unsupervised and supervised baselines based on TF-IDF features and pre-trained BERT embeddings. Furthermore, we show it can be applied for multilingual (e.g., English-to-English alongside Dutch-to-Dutch) and cross-lingual matching (e.g., English-to-Dutch and vice versa).
Finally, we show that using a regression objective to optimize for cosine similarity yields more useful embeddings in our scenario, where we aim to apply the learned embeddings as feature representation in a broader job recommender system.



