.svg)

30-11-2022
4 april 2023
The popularity and adoption of open table formats, such as Iceberg, Delta Lake, and Hudi continue to rise, due to their advanced features and capabilities. The Data and Analytics Platform team within Randstad Groep Nederland has migrated the Data Lake from Apache Hive Metastore managed parquet files into the Apache Iceberg table format.
This blog explains the motivation behind the migration. The shortcomings of the past and the benefits of the present setup are also described.
The popularity and adoption of open table formats, such as Iceberg, Delta Lake, and Hudi continue to rise, due to their advanced features and capabilities. The Data and Analytics Platform team within Randstad Groep Nederland has migrated the Data Lake from Apache Hive Metastore managed parquet files into the Apache Iceberg table format.
This blog explains the motivation behind the migration. The shortcomings of the past and the benefits of the present setup are also described.
Past — Hive
The data lake was previously based on parquet files stored on S3 and the Apache Hive compatible AWS Glue Data Catalog. The setup relied on the Hive folder-like directory structure, as shown in Figure 1. However, our experience with this format revealed several drawbacks, namely:
- Trino is the data lake query engine. In order for a Trino query to discover the files required, the partitions need to be listed at runtime. Especially for tables with many partitions, this is not only time consuming (O(n)), but also costly, due to the cost introduced by the S3 API calls required to list the objects.
- The table metadata is stored in the Hive compatible AWS Glue Data Catalog metastore. To track the partitions and keep the metastore up-to-date, we were using AWS Glue Crawlers, which is an extra component in the data pipelines, that also incurs costs and introduces a delay in the ingestion process due to runtime.
- The current zone of the Data Lake stores the up-to-date state of the data, for example the last Update of the records. To build it in the Hive structure, the previous snapshot gets loaded in memory, the current state gets computed and the snapshot is written back on S3. This led to significant S3 I/O and increased load on the EMR cluster where we run our Spark jobs.
- Hive tables do not support ACID transactions, which can lead to data inconsistencies or even data loss if multiple writers attempt to update the data concurrently.
- Modifying the partition granularity requires a full data migration. For example, if the existing partition is /year/month/day/hour/minute, modifying it to /year/month/day requires a full rewrite of the data, which is resource-intensive and time consuming.

Figure 1. Hive table structure [1]
Present — Iceberg to the rescue
Due to the aforementioned reasons we decided to look into Apache Iceberg, an open table format created by Netflix to address many of the Apache Hive shortcomings. In a nutshell, the magic of the Iceberg architecture (see Figure 2) relies on the metadata layer, which holds metadata for all the table files, but also information about each individual file, as well as column-level metadata.
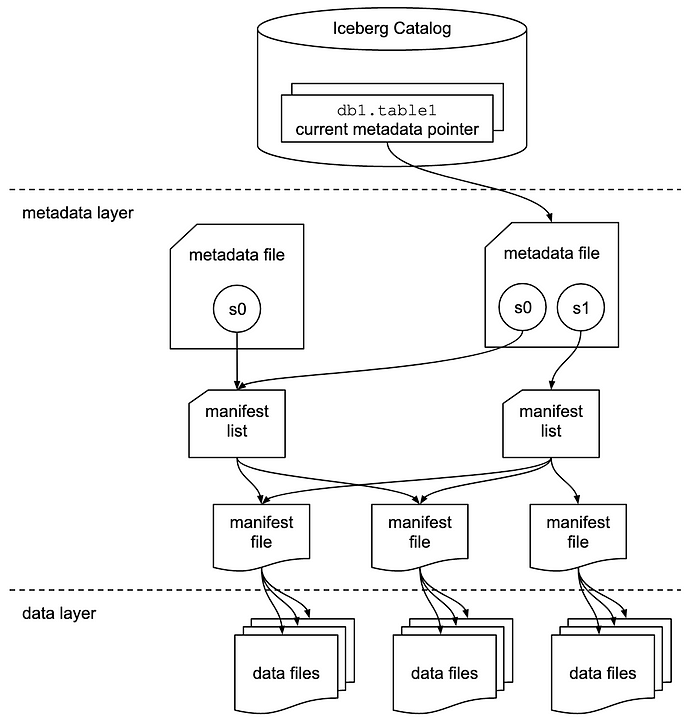
Figure 2. Iceberg Architecture [2]
Most importantly, Iceberg improves user experience and leads to cost reductions. Some of the major advantages identified are listed below:
- Full directory scanning is not needed, therefore S3 API costs are lower and query planning is faster. We noticed an average 35% improvement in Trino query runtimes.
- Iceberg uses ACID transactions. Many processes can update the data at the same time and we can rest assured that all transactions are atomic, consistent and isolated.
- An expressive Spark SQL MERGE INTO statement can be used to do an UPSERT and create the current snapshot of the data. Less I/O is required, which translates into cost reduction.
- Users can easily time-travel and examine the data at an earlier point in time.
- Table rollback can be done to revert the table state, for example in case of an erroneous data ingestion.
- Schema evolution is seamless, “HIVE PARTITION SCHEMA MISMATCH ERROR” anyone?
- There is no need to run Glue Crawlers or to create Hive views that point to the current state of the data.
- Partition evolution can be used to modify the partition layout on-the-fly, avoiding a costly operation.
Conclusion
Apache Iceberg is a great tool for managing large data sets in a data lake. It has greatly improved consistency, scalability, performance, and maintainability in our Data Platform. If your data lake is currently based on Hive, consider adopting Iceberg!
References:
- https://www.dremio.com/resources/guides/apache-iceberg-an-architectural-look-under-the-covers/
- https://iceberg.apache.org/spec/


